I Built an AI System to Read My Health Insurance Policy. Here Is What It Took.
A multi-pass LLM extraction pipeline for Indian health insurance policy booklets, and the specific decisions I made along the way
I have a health insurance policy. I have renewed it three times. I have never read it.
Not all of it. Nobody reads all of it. The booklet is 54 pages. Page one is a welcome letter. Page two has a table of contents with entries like “Section 4.3.2(b): Proportionate Deduction.” By page three you have already decided you will figure it out when you actually need to file a claim.
The problem with that plan is that page 47 contains a table that will determine how much you pay out of pocket during your hospital admission. And you find this out at 11pm, the night before a procedure, when the hospital billing desk calls to explain your room choice.
I got tired of this. So instead of reading the policy, I spent significantly more hours building an AI system to read and interpret it for me.
What I built and why
Health Copilot is a React Native app I am building for the Indian market (with help from my friends ClaudeCode, OpenCode and Codex). The premise is simple: upload your health data, ask questions in plain language, get grounded answers. I have built the parsers for prescription and lab reports; which while not trivial, were not really that difficult to implement.
The hard part is building an entire ingestion+parsing pipeline for health insurance booklets, which can be dozens of pages long. Getting a multi page PDF into a form that an LLM can reason about accurately, without hallucinating rupee amounts or inventing waiting periods that do not exist, turned out to be the interesting problem. And considering I have already faced similar problems in my day job while working on AI solutions for US Health Insurance ecosystem, I took it up as a challenge to find a fix for the Indian context.
This post is about that.
Why this is a product problem, not just a parsing problem
It is tempting to frame this as a document AI problem. OCR the PDF, send it to an LLM, extract some fields, move on. Technically, yes. But the actual user problem is not “can the model parse a document.” It is “can I trust this answer when a hospital bill is involved.”
That distinction matters. If an LLM gets a movie runtime wrong, nobody cares. If it gets your room rent limit wrong, you may discover the mistake only when the claim is partly denied. In health insurance, accuracy is not a nice to have feature. It is the product.
That changed how I designed the system. I was not building a summary generator. I was building something that had to earn the right to answer a narrow class of stressful, high consequence questions.
The naive approach, and why it fails
The first thing you try is: send the whole document to an LLM and ask it to summarize.
This works about as well as asking someone to summarize a legal contract they have never seen, in thirty seconds, while you wait. The model will produce something that sounds right. Some of it will be right. The parts that are wrong will be the parts that matter most: the specific sublimit on cataract surgery, the exact waiting period for joint replacement, whether the proportionate deduction clause applies to your plan or not.
Insurance policy documents are designed to be precise. An LLM summarizing one is, at its best, approximating that precision. At its worst, it is confidently wrong about a number that will show up on your hospital bill.
So you do not send the whole document. You build a pipeline.
The pipeline
Here is what actually runs when a user uploads a policy PDF:
Each step exists because I hit a specific failure mode in a previous version. The OCR layer is a three-tier fallback because no single provider handles every policy PDF well. Google Document AI is the default; it preserves table structure and column alignment, which matters enormously for room rent and sublimit tables. When it is unavailable, the system falls back to unpdf, which extracts the embedded text layer from digital PDFs without any layout intelligence. This is fast and free and loses all your table formatting, which is a meaningful trade off. For truly scanned documents where unpdf returns empty, an OpenRouter vision call using Gemini 2.5 flash lite handles OCR as a last resort.
Semantic chunking replaced fixed size chunking after the LLM started returning financial limits from the middle of an exclusions table. Multi pass extraction replaced a single monolithic prompt after I got sick of the model forgetting to extract waiting periods when it was also trying to extract network rules and contact information.
Every layer is scar tissue from a previous mistake.
The pipeline in action
Upload → “AI extraction in progress” → “Extraction complete” → Policy Details with confidence score
Behind the scenes: While the user navigates away, the seven pass state machine runs through its sequence. Here is what the pass logs look like for an actual extraction:
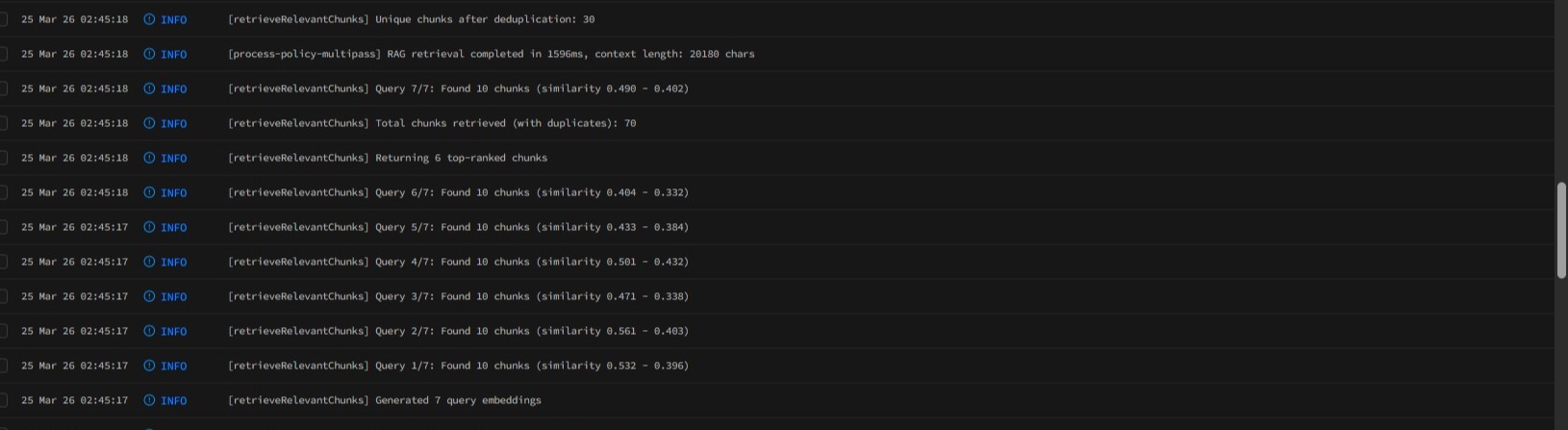
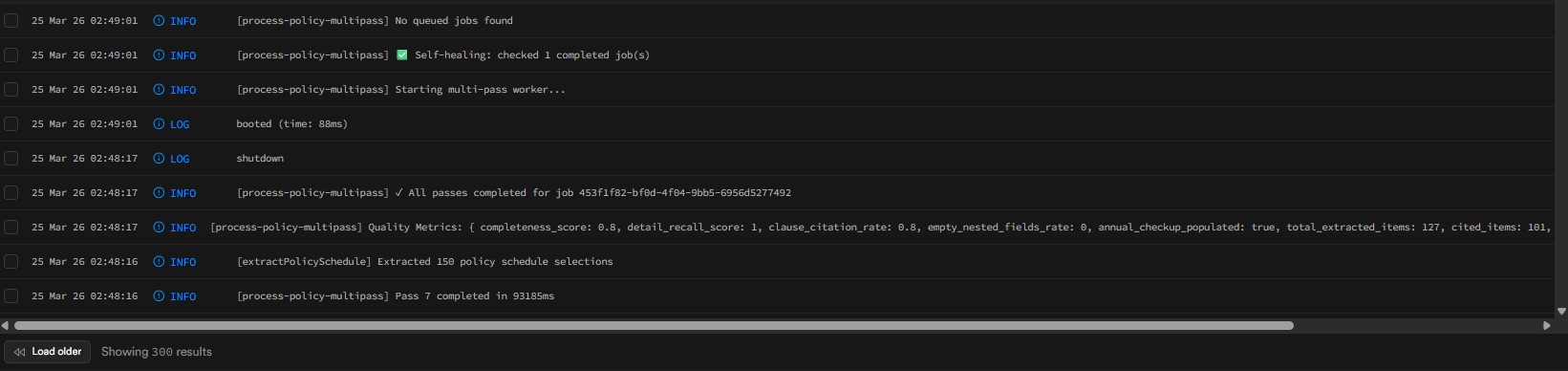
Pass 1 (Policy Identity) through Pass 7 (Policy Schedule), with durations and model assignments for each. The cron worker picks up state transitions every minute until completion.
Chunking, and why the way you split a document matters more than you think
Fixed size chunking is the default in most RAG tutorials. Split every N tokens, store the chunks, embed them, retrieve on similarity. It is fast and it works fine for prose documents.
It is catastrophic for policy documents.
A health insurance policy is mostly tables. Room rent limits are in a table. Waiting periods are in a numbered list that runs across two pages. Exclusions are in a nested clause structure where the parent clause qualifies every child clause. Split any of these in the wrong place and the chunk you retrieve no longer means what it said before you split it.
The semantic chunker I built detects structure first:
- Tables: kept together, split on row boundaries only if unavoidable
- Lists: split on item boundaries
- Prose: split at sentence boundaries with a 150 character overlap
Each chunk also gets metadata attached automatically. Whether it contains rupee amounts. Whether it contains durations like “months” or “waiting period.” Which section type it belongs to. Which other clauses it cross references.
interface ChunkMetadata {
section_type: 'benefits' | 'exclusions' | 'waiting_periods'
| 'financial_limits' | 'definitions' | 'other';
chunk_type: 'table' | 'list' | 'prose';
contains_amounts: boolean;
contains_durations: boolean;
cross_references: string[];
section_hierarchy: string[];
}The contains_amounts and contains_durations flags sound trivial. They are not. When a user asks “what is my room rent limit,” filtering to chunks where section_type === 'financial_limits' && contains_amounts === true before similarity search is the difference between retrieving the right table and retrieving the paragraph that merely mentions the word “limit” in passing.
Seven passes, but not all in the same way
The extraction engine has seven passes overall, but the first one is different. Pass 1 runs immediately at upload time in process-policy-parse and extracts the policy’s identity: insurer name, policy number, plan name, members, dates, sum insured, premium amount, and the basic contact information that usually sits in the welcome-letter section.
Passes 2 through 7 run through process-policy-multipass. Each invocation handles exactly one pass, updates a current_pass counter in the state table, and exits. The cron worker sees the updated state and re-invokes the function for the next pass. It is a state machine, not a loop.
This is not the elegant design I intended. I started with one pass: send everything, get everything back. It timed out. I split it into two. Those timed out. Three. Still timing out. I kept splitting until each individual function call was narrow enough to complete within the Edge Function timeout window. Seven is where I landed.
The cron worker is pg_cron because Edge Functions do not support long-running background work. A pg_cron job polling a Postgres state table is the simplest durable mechanism available in the Supabase stack: no separate queue infrastructure, no Redis, no additional service to keep alive.
The state machine is what makes it resilient. Failed passes increment an attempts counter. After 15 attempts the job is marked failed with error details. Results are merged into documents.extracted_data immediately after each pass completes, so if pass 5 fails, passes 1 through 4 are not lost.
| Pass | What it extracts | Model |
|---|---|---|
| 1 | Policy Identity: insurer, plan, members, dates, sum insured, premium, basic contacts | Standard |
| 2 | Advanced Benefits: maternity, wellness, loyalty bonuses, branded add-ons | Standard |
| 3 | Financial Limits: room rent, sublimits, co-pay | Strong |
| 4 | Waiting Periods + Exclusions: combined, with separate reasoning over each | Strong |
| 5 | Network & Operations: pre-auth, cashless, claims workflow, contact recovery | Standard |
| 6 | Covered Benefits: full procedure/condition list plus non-payable items | Strong |
| 7 | Policy Schedule: the feature table of covered / not covered options | Standard |
Standard = openai/gpt-4o-mini, Strong = openai/gpt-4o
Passes 3, 4, and 6 are the highest weighted categories in the completeness score. They get the strong model. This is a deliberate resource allocation decision, not a default choice.
The retrieval strategy is different by pass. Passes 2 through 5 use RAG: generate semantic queries for the current domain, retrieve the most relevant chunks from pgvector vector database, add neighboring chunks for context, deduplicate, then send that focused context to the model.
Passes 6 and 7 do the opposite. They use full OCR text instead of RAG because these are broad list-and-table extraction problems. Covered benefits and policy schedule tables are exactly the kind of content that chunk retrieval can fragment in unhelpful ways.
There are also a few ugly but effective reliability hacks. In pass 4, the initial waiting period is overridden from a direct OCR string lookup because the LLM kept paraphrasing the 30 day clause in slightly different ways. In pass 5, contact info is mostly regex-corrected from OCR after the model responds, and there are targeted fallback retries for claims and pre-auth sections when the first attempt comes back thin.
The extraction builds on itself. Embeddings are generated up front from the OCR text in the first pass via OpenRouter’s embedding endpoint using text-embedding-3-small (1536 dimensions), batched in groups of 50, and stored in Supabase pgvector. Later RAG passes query that index, and the same vector store also powers copilot chat.
The JSON parsing problem
LLMs return malformed JSON more often than you would hope. Especially when reasoning about tables with irregular structure and amounts formatted with commas. I built a safe JSON parser that does the following, in order:
- Try direct parse
- If that fails, find the first
{and last}in the response - Remove null bytes, trailing commas before
}or] - Try parse again on the cleaned substring
- Log a context-tagged error if that also fails
This is unglamorous. It also prevented a meaningful percentage of extraction failures that would have otherwise surfaced as “policy could not be parsed” errors. Unglamorous things often work.
Completeness scoring
After all passes complete, the system calculates a completeness score. This determines how confidently the app can answer questions about the policy.
The weighting reflects what matters at claim time:
| Category | Weight | Why |
|---|---|---|
| Financial Limits | 25% | Determines your out of pocket exposure |
| Waiting Periods | 25% | Determines whether a new claim will be rejected |
| Exclusions | 25% | What the insurer will refuse to pay |
| Network & Operations | 15% | Preauth, cashless hospital rules |
| Advanced Benefits | 10% | Wellness, maternity, bonuses |
Beyond the primary score, the system also computes additional quality metrics: Detail Recall Score, Clause Citation Rate, and Empty Nested Fields Rate. These are stored alongside per pass metadata (duration, model used, context length, whether RAG was active).
A low primary score surfaces a message to the user explaining which sections may be incomplete. This is the kind of product decision that sounds obvious once you state it, and that I did not make until I tested the app with a policy that had non standard exclusions formatting and got back a 40% score with no indication anything was wrong.
Evaluating the policy parsing
The completeness score tells the app when it might be wrong. That is not the same as knowing when it is wrong.
There is a specific category of software bug that is invisible when you are informally reading output. The extraction looked reasonable. The JSON had values in the right fields. Some of those values were incorrect. I only knew this because I eventually stopped looking and started measuring.
So I built an eval pipeline.
The ground truth is a JSON file I compiled manually: 22 Tier A fields (the ones that matter at claim time: sum insured, room rent, waiting periods, exclusions, co-pay, premium, policy dates, covered services, pre-auth, exclusions, limits, etc.) and 6 Tier B fields (wellness benefits, TPA contact details, policy schedule features). A Deno script connects to Supabase, fetches the extracted JSON, resolves each field through a registry of parser path aliases, normalizes the values, and reports a match status for every field.
The normalization step is important and unglamorous. Indian insurance documents store currency as ₹10,00,000 (the lakh comma format). Dates are DD/MM/YYYY. Often, LLMs parse these values incorrectly, unless given proper context and instructions on how to handle them. Phone numbers come with inconsistent spacing, country code prefixes, and hyphens in random places. A literal string comparison against ground truth would fail everything. The normalizers convert all of this to canonical forms before comparison, so ₹10,00,000 and 1000000 and Rs. 10 Lakh are treated as the same value.
The baseline was 50%.
The first run passed 11 of 22 Tier A fields. This was alarming. Looking at JSON output and measuring it are different activities, and I had been doing the former and calling it validation.
The failures revealed a category of bug I had not thought to look for: field name mismatches. The extraction prompt was returning insurer but the rest of the pipeline expected insurer_name. The merge function was silently overwriting correctly extracted values with null because the key names did not match. Invisible when you read the output casually. Immediately visible when you run a structured comparison against ground truth.
Getting from 50% to 90.9% took three phases. One the most instructive failures along the way:
The initial waiting period was failing because the LLM paraphrased the clause. The policy says verbatim: “Expenses related to the treatment of any Illness within 30 days…” The model returned: “30 days for any Illness.” Both correct in meaning. The eval flagged it as a mismatch. The fix was an OCR indexOf lookup that anchors to the verbatim clause text directly; the LLM does not get to rephrase a specific clause when the exact wording is already in the document.
The gate I set was Tier A ≥ 90%: 20 of 22 fields must pass. The pipeline crossed it and held there across 10 independent uploads of the same document with 3 different models (gpt-4o, gemini-2.5-flash, Kimi K2.5) which is the test I actually care about, not a one time lucky run, but consistent output on fresh input, irrespective of the model used.
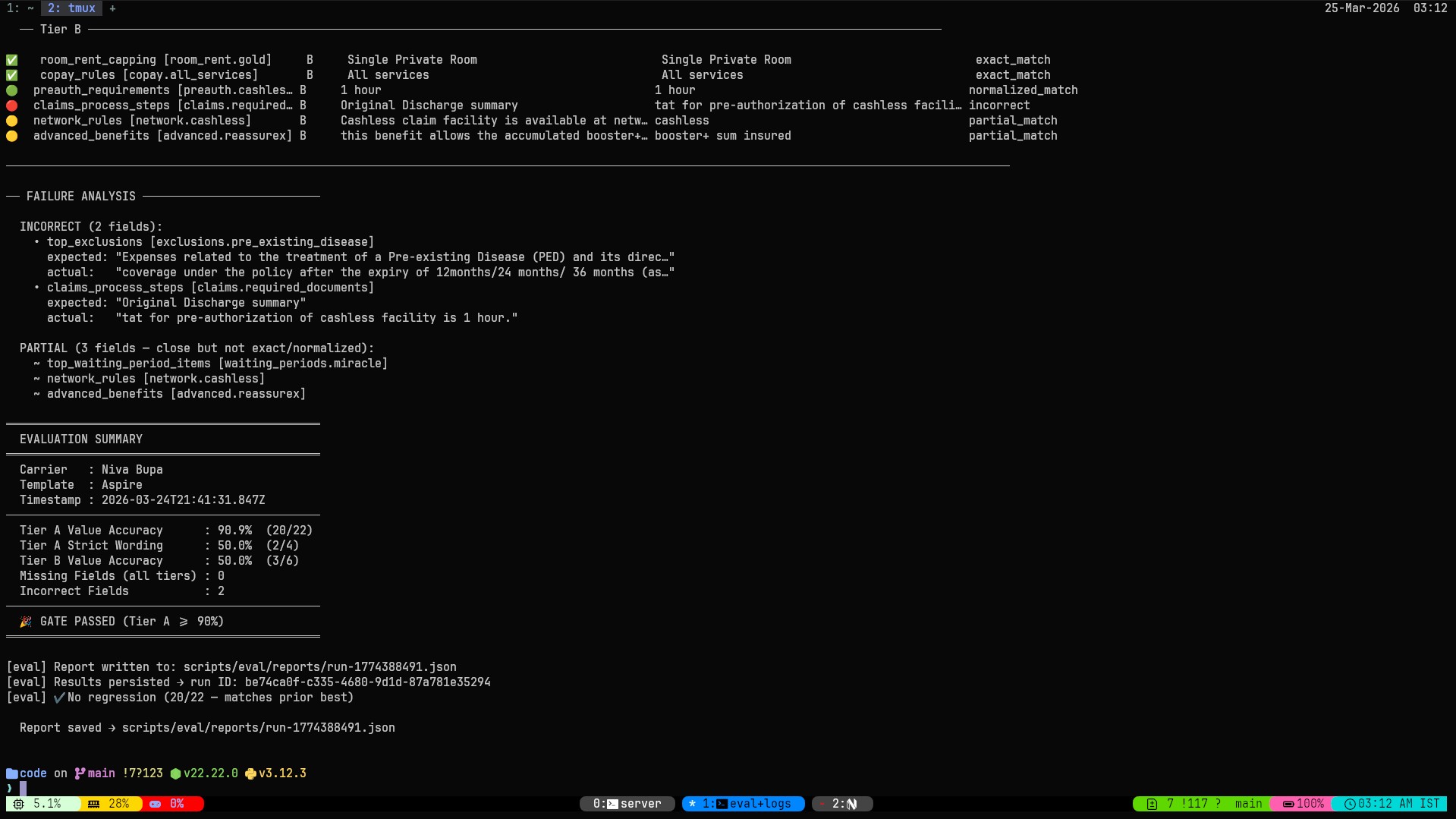
The eval report for a Niva Bupa ReAssure policy. Green = exact match after normalization. Yellow = acceptable variation (e.g., “10,00,000” vs “1000000”). Red = missing or incorrect. The initial_waiting_period field initially failed because the LLM paraphrased the clause; the fix anchors to verbatim OCR text.
Running a structured eval changed something about how I think about this system. Before it, I had intuitions about what was working. After it, I had data. Those two things do not always agree, and the disagreements are exactly where the interesting bugs live.
How the chat actually answers your question
Once the extraction pipeline finishes and the completeness score is calculated, the app is ready for a completely separate system: the copilot chat. The parser figured out what your policy says. The copilot figures out what you are actually asking, and why.
These are different problems.
The naive approach is to dump the extracted JSON and your question into one big prompt and hope for the best. This works for simple questions. For anything more specific (like “what is my room rent limit if I upgrade to a private room during an emergency admission”), you need the model to understand the structure of your question, retrieve the right clauses, and reason about them correctly before it responds.
Here is what actually runs when you send a message:

The copilot in action
Three questions: “What is my room rent limit?” → “Can I claim for cataract surgery?” → “What if I upgrade my room during emergency admission?”
NOTE : The copilot responses have little high latency in the video above due to COTs debugging being enabled in the logs. This was done for the demo to show how the model uses the COTs reasoning framework to work through the user question. Enabling the debugging mode leads to few more LLM calls, which leads to few more seconds for the responses to be generated.
Notice how the third answer cites specific clauses and conditions. Here is what the reasoning layer looks like in the logs:
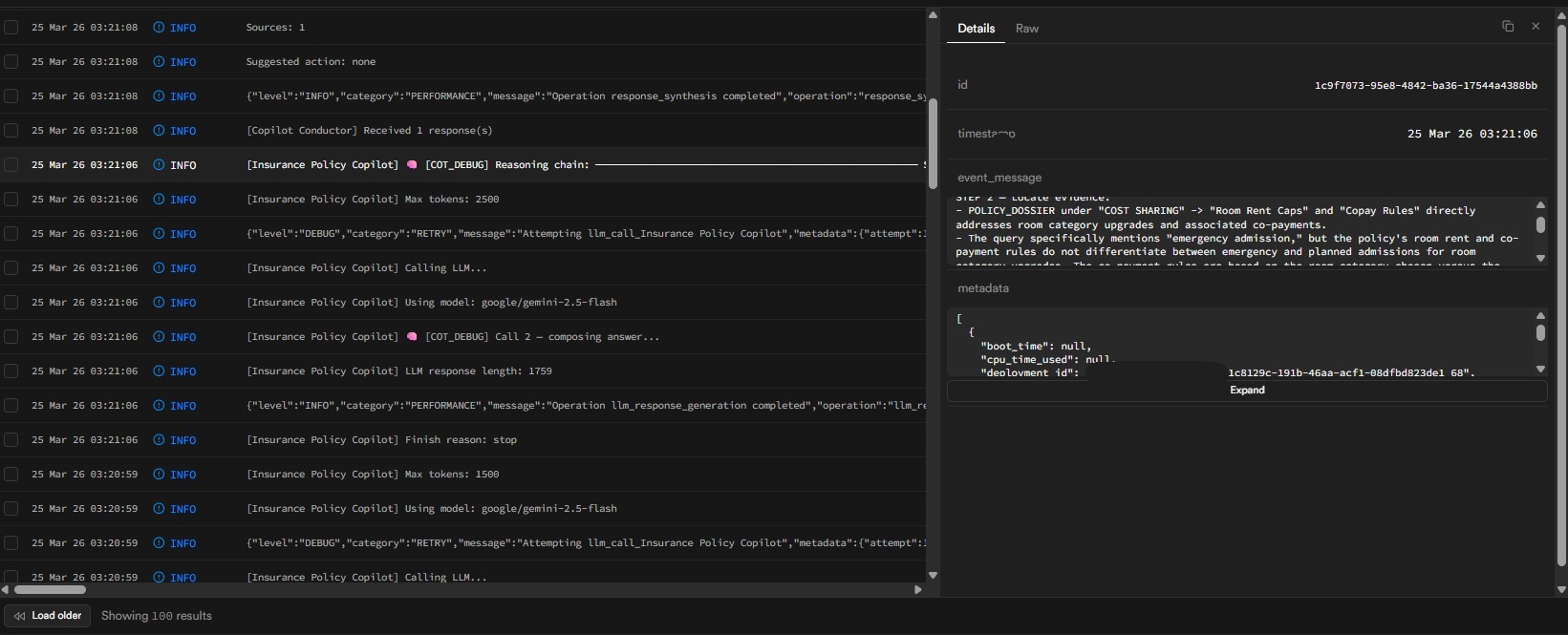
The model works through intent parsing, dossier checking, excerpt review, sub-clause reasoning, and answer formulation. Users never see this.
A few things about this are worth explaining.
The intent classifier runs first, on every message, using a cheap fast model (gpt-4o-mini, max_tokens: 300). Its job is not to answer the question. It is to route it. If confidence falls below a configurable threshold (default 0.65 for new conversations, 0.50 for follow-ups in an active conversation), the system returns a clarifying question rather than an answer.
If the classifier returns a CRITICAL urgency (chest pain, stroke, unconscious, diagnose mental disorder, etc.), it bypasses everything that comes after: no conductor, no RAG retrieval, no response generation. The hardcoded first responder instructions go back immediately. These are both deliberate decisions. The first prevents the model from hallucinating an answer to an ambiguous question. The second prevents a health app from giving the user a diagnosis, something that the models can’t ever be allowed to do.
The dual source context is the part I am most pleased with. The POLICY_DOSSIER is the structured output of the extraction pipeline (organized, deduplicated, already processed). RELEVANT_POLICY_EXCERPTS are raw OCR chunks retrieved by semantic similarity and then re-ranked. The two sources complement each other: the dossier gives organized signal, the excerpts give verbatim clause text that the model can cite directly.
Using only the dossier means losing clause wording. Using only RAG means losing the organized extracted fields. Using both means the model has access to what the parser understood and what the document actually says.
The two stage retrieval that populates the excerpts looks like this:
// Stage 1: pgvector cosine similarity retrieves 20 candidates
// Stage 2: Cohere cross-encoder selects the best 5 by true relevance
// Graceful degradation: falls back to cosine top-5 if key is absent.
async function rerankWithCohere(
query: string,
candidates: PolicyExcerpt[], // 20 cosine candidates
topN = 5
): Promise<PolicyExcerpt[]> {
if (!cohereApiKey) return candidates.slice(0, topN); // fallback
const response = await fetch('https://api.cohere.com/v2/rerank', {
method: 'POST',
headers: { Authorization: `Bearer ${cohereApiKey}` },
body: JSON.stringify({
model: 'rerank-v3.5',
query,
documents: candidates.map(c => c.chunk_text),
top_n: topN,
}),
});
return (await response.json()).results.map(
(r: { index: number; relevance_score: number }) => ({
...candidates[r.index],
similarity: r.relevance_score, // cross-encoder score replaces cosine score
})
);
}The re-ranker is Cohere’s rerank-v3.5. I am using it because vector similarity does not equal relevance. The top pgvector candidate for “room rent limit” will be some chunk with the words “room” and “rent” in close proximity, which might be a clause header with no actual numbers. The re-ranker sees all 20 candidates together and scores them by how useful they are for the specific query. The top 5 after re-ranking are meaningfully better than the top 5 by cosine similarity alone.
The reasoning framework deserves a note. The model does chain-of-thought reasoning on every policy question: it works through intent, checks the dossier, reviews the excerpts, reasons about sub-clauses, then formulates a response. None of this is visible to the user. The system prompt ends with: OUTPUT: Write only the final answer. Do not expose your reasoning steps in the response. The internal thinking gets suppressed. Users see a clean answer with citations.
If I need to debug a wrong conclusion, there is a COT_DEBUG flag that replaces the suppression line with an instruction to label each reasoning step explicitly, which produces a very different, very verbose response that I find extremely useful and that no actual user should ever see.
Some honest observations about the current state. When the intent confidence is too low and the system asks a clarifying question, it returns plain JSON instead of a streaming response. The client handles this gracefully now, after a bug where empty assistant bubbles appeared. There are also occasional citation quality issues; the re-ranker will sometimes surface an excerpt that is topically adjacent but not the clause the user needed. And the Cohere re-rank call is one more API hop with its own latency. The full response cycle runs against a 45-second LLM timeout and a 20-second embedding timeout, which are not small numbers on mobile.
The copilot is slower than the parser. The parser runs once, asynchronously, and you wait for it. The copilot runs on every message, synchronously, and you wait for it every time. At some point that latency is what users actually notice, not the extraction accuracy.
The product decisions that mattered more than the model
The interesting part of building with LLMs is usually not the prompt. It is deciding where the model is allowed to be clever and where it is absolutely not.
Three decisions mattered more than any prompt wording I used.
First, I optimized for reliability over elegance. A seven pass state machine is less aesthetically pleasing than one clean function call. It is, however, much more useful when your infra has timeouts and your users would like the answer before discharge.
Second, I treated confidence as a product feature. The completeness score is not there because dashboards enjoy percentages. It is there because the app should know when it may be wrong, and say so before the user trusts an incomplete answer.
Third, I did not let the LLM be the final authority on fields that OCR or regex can recover more deterministically. If a phone number can be regex-corrected and a 30 day waiting period clause can be anchored directly in OCR text, then the model does not get a vote. This offended the part of my brain that likes elegant abstractions. It also improved the output, which is annoyingly more important.
What’s still remaining
Currently, the parsing pipeline has been tested with only two insurers: Niva Bupa Health and Star Health. The TIER A gate for policy documents for both the insurers is consistenly above 90%. The parsing pipeline will have to be stress tested with booklets from other insurers, preferrably documents that have a wildly different layout and format from Niva Bupa Health and Star Health. With more testing iterations and improvements to the ingestion and parsing pipeline, I believe achieving >90% accuracy across new policy documents is realistic. At the end of the day, the blocker to do so is not technology, but rather blockers related to data and testing resources.
There are entire categories of edge cases I have not touched. Password-protected PDFs, corrupted files, documents that run to two hundred pages. I do not know what happens when these hit the pipeline. They are sitting in a mental backlog labeled “deal with it when it breaks.” For a production system this would be unacceptable. For a solo builder working in evenings and weekends, it is a deliberate constraint.
The same logic applies to the retry strategy: failed passes are logged to a Supabase table and picked up by a cron job after twenty-four hours. Not because this is optimal, but because I did not want to be woken up by logs while building for myself.
The validation, on the other hand, is stricter than it sounds. I spent ten years as a business analyst, data analyst, consultant, and product manager in the US health insurance space. When I say the extraction is validated against a “golden” JSON, I mean I wrote that JSON by hand, cross-referencing against actual policy language I have learned to read with unhealthy precision.
The latency numbers tell their own story. The full seven pass pipeline takes roughly ten minutes end-to-end. I believe, and I may be wrong here, it is acceptable here because policy documents are uploaded four or five times a year, the work happens asynchronously, and users can close the app entirely while the cron worker continues its state machine transitions. When they return, the confidence score is displayed as a chip on the document details page, a UI level disclosure that this extraction may be incomplete.
The latency for copilot chat is, to be honest, unacceptable. With dual-context assembly and COTs reasoning framework, the responses are slow, but highly accurate. Those are product features and something I am not willing to sacrifice. There are a few solutions I have thought about which can reduce the latency, but have not experimented with them yet, for e.g. using an inference provider with higher Token Per Second (TPS) throughput like Groq or SambaNova.
I have also not measured p95 latencies, neither have I stress tested with hundred user concurrency. So many of the “crossing the t’s and dotting the i’s” tasks one must do before letting a product go live haven’t been completed. I intend to pick them up when I get some free time (or this idea does turn into an actual startup idea).
What I would measure if this goes into production
If this goes into production, I would care about four metrics more than anything else.
Question coverage. What percentage of user questions can the system answer with grounded citations from extracted policy data or retrieved OCR chunks?
Answer trustworthiness. Of the answers given, how many are judged correct on manual audit for the highest stakes categories: room rent, waiting periods, exclusions, co-pay, cashless rules?
Parser failure patterns. Which insurers, PDF types, or section categories consistently underperform? I want failure to be diagnosable, not mysterious.
User behavior after the answer. Do people stop after the first question? Do they ask follow ups? Do they revisit the same policy before a hospital event? The parser can extract clauses. It cannot, by itself, prove that the product is useful.
That last one is the uncomfortable metric. It is possible to build a technically competent system for a problem that nobody wants to solve this way. Product management is, among other things, the repeated discovery of exactly that possibility.
What I learned about Indian health insurance documents
Building this forced me to read more Indian health insurance policies carefully than I have read anything in recent memory. Some observations:
The four things that will surprise you at claim time are the ones nobody tells you about when you buy: the room rent sublimit (often 1% of sum insured per day, which caps out well below what private hospital rooms cost), the proportionate deduction clause (which reduces your claim amount if your room costs more than your limit, applied to the entire bill, not just the room), disease-specific waiting periods (cataract, hernia, joint replacement (typically 2 years)), and the co-pay for senior citizen add-ons (10%, applied to every claim, forever).
All of this is in the policy. You signed the policy. Nobody reads the policy.
“Covered” almost always has a subordinate clause. Maternity is covered, subject to 9 months of continuous membership. AYUSH treatment is covered, subject to hospital empanelment requirements. Modern treatment methods are covered, subject to a sublimit that is not on the same page as the coverage statement.
The structure is completely inconsistent across insurers. Star Health, HDFC Ergo, ICICI Lombard, Niva Bupa. They each have different section names, different clause numbering schemes, different ways of formatting the same information. This is why the keyword fallback to full OCR text exists. It is also why a solution that hardcodes section names for one insurer’s format will break on every other insurer’s format.
Conclusion
The extraction pipeline works. For the policies I have tested, completeness scores are in the 70-90% range for well-formatted digital PDFs, lower for scanned documents with degraded OCR quality. The copilot chat answers questions accurately when the relevant information was extracted. It cites sources. It does not make up numbers.
Whether anyone will use it, whether Indian consumers want to interact with their health insurance policy at all, whether the product form factor is right. Those are separate questions that the parser cannot answer.
What I do know is that I understand Indian health insurance policies significantly better than I did before I built this. Which is, at minimum, not nothing.
The answers are in the policy booklet itself. They have always been in there. They are just on page 42.